#diamonds : 54,000개 다이아몬드 각각으 가격, 캐럿, 색상, 투명도 등 정보를 가진 Data Set diamonds
[ 참고 사항 ]
ggplot2는 보통 ggplot(data=<데이터>)에 지옴 함수를 + 하여 작동
→ 즉 그래프 형식을 변경하거나 표현을 추가하고 싶다면 +되는 지옴함수를 바꾸면 됨
막대 그래프 그리기 ( geom_bar() )
막대그래프는 범주형 자료들을 한 눈에 비교하여 볼 때 유용하다. ggplot2에서는 아래와 같이 geom_bar() 함수를 활용하여 쉽게 구현 가능하다.
# geom_bar 활용 막대 그래프 작성 ( cut에 포함되는 범주들을 Count하여 구분 ) ggplot(data=diamonds)+geom_bar(mapping = aes(x = cut))
특이한 점이 보인다. Count라는 변수는 선언하지도 않았는데, 저절로 범주별 Count를 진행하였다. 여기서 알아야할 개념이 '스탯 = 통계적의 줄인말 = stat ' 이다. ggplot2에서 스탯이란 ' 그래프에 사용될 새로운 값을 지정해 나가는 과정'을 의미한다. 위처럼 cut 변수만 지정하였는데, Count 변수가 저절로 생긴 이유는 geom_bar()에는 기본으로 count 스탯이 있기 때문이다. 아래처럼 지옴과 스탯을 바꾸어 작성해도 결과는 같다.
요약 값 ( Min, Max, 중간값 ) 등에 집중시키고 싶다면, stat_summary를 사용해도 좋다.
ggplot(data=diamonds) + stat_summary( mapping = aes(x=cut, y=depth), fun.min = min, fun.max = max, fun = median )
geom_bar()와 비슷한 함수 중 geom_col() 도 있다. Bar와 col의 차이는 통계적으로 변환을 하냐, 안하냐 차이다. 따라서 Col 같은 경우 매핑 시 2개의 변수를 지정해주어야 하는데, Bar의 경우 한 개의 변수만 지정해 주어도 기본 통계적 변수로 알아서 변환해 준다.
# geom_bar은 스탯 활용, X축만 입력해도 통계적 변환 후 그래프에 표시 # geom_col은 Data를 통계적 변환하지 않고 그대로 표시
산점도, 기하 그래프를 학습할 때, 항상 학습한 것이 있다. 그래프에 한가지 변수를 더 추가하여 구분하는 것이다. geom_bar()에서는 Fill 변수에 구분하고자 하는 변수를 입력하면 된다. ( 색상은 랜덤 )
# Cut 변수를 Cut 변수로 구분, 즉, 각 범주마다 색상 입히ggplot(data=diamonds) + geom_bar(mapping = aes(x=cut, fill=cut))
# 막대그래프 상 Clatity 변수로 색상 구분 ggplot(data=diamonds) + geom_bar(mapping = aes(x=cut,fill=clarity))
위의 막대 그래프는 한 변수 위에 다른 변수가 축적된 누적 막대그래프이다. 누적 막대그래프가 아니게 표현하고 싶다면, Position을 "identity", "dodge", "fill" 등으로 지정해주면 된다.
먼저 "identity"를 살펴보자. "identity"는 누적 막대그래프가 아닌 변수마다 0부터 시작하게 포지션을 잡고, 같은 범주끼리 묶어버린다. 아래 그래프를 보면 직관적으로 이해가 가능하다. ( 잘 보기 위해선 투명도도 추가 하자 )
# 누적 막대그래프가 아닌, 중복 막대그래프 그리기 # 외쪽 Count 범위를 보면 지정 안했을 때와의 차이를 알 수 있다. ggplot( data=diamonds, mapping = aes(x=cut, fill = clarity) ) + geom_bar(alpha = 1/5, position = "identity")
동일한 기준에서 범주마다 한 변수의 비율을 비교하고 싶다면, Position을 "fill"로 지정하면 된다.
ggplot( data=diamonds, mapping = aes(x=cut, fill = clarity) ) + geom_bar( position = "fill")
[ 사용 형식 ] ggplot(data=<데이터>) + <geom_함수>(mapping = aes(<매핑모음>))
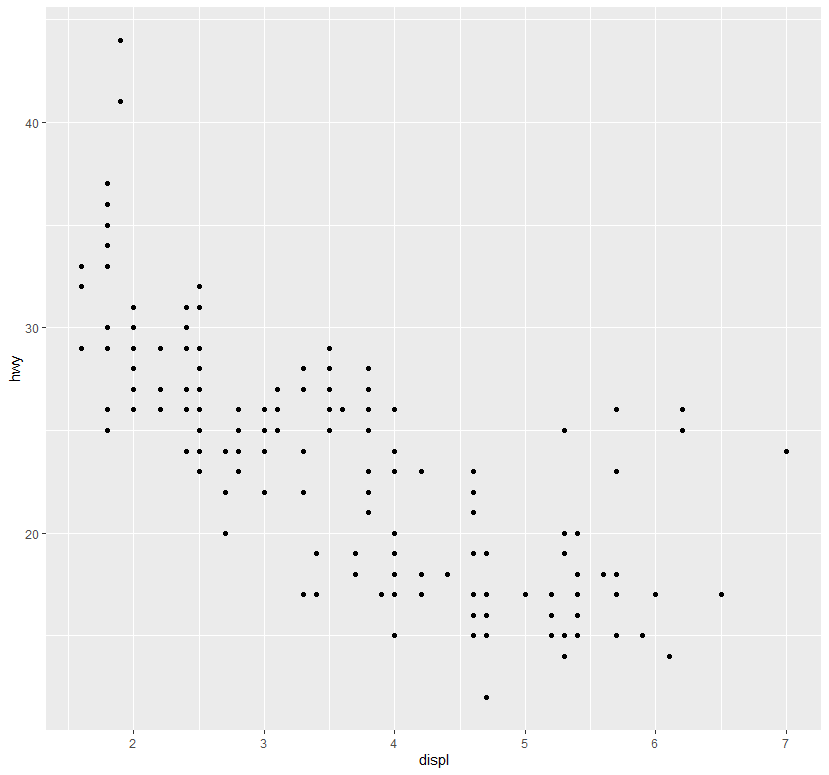
geom_point() 함수로 산점도를 작성해보면 배기량(displ)과 연비(hwy)가 음의 상관관계가 있음을 알 수 있다.
# geom_point() = Plot에 점 레이어 추가, 산점도 생성 # aes()의 x, y 인수는 x, y축으로 매핑될 변수를 지정 ggplot(data=mpg) + geom_point(mapping = aes(x=displ, y = hwy))
위 산점도를 보면, 점들이 이상하게 규칙적이다. 그 이유는 geom_point()는 값들을 반올림하여 나타냈기 때문이다. 반올림하는 이유는 점들이 겹치는 것을 방지하기 위함이라고 한다. 그러면 실제 값을 산점도에 표현하려면 어떻게 해야할까? 지옴 함수를 geom_jitter()로 바꾸어주면 간단히 해결된다.
<참고> geom_jitter()를 통해선 실제 값으로 산점도 표현이 가능하다.
ggplot(data=mpg) + geom_jitter(mapping = aes(x=displ, y = hwy))
다시 geom_point()로 돌아와서, 산점도에 색상을 표시해 차형식(Class) 도 함께 구분해서 보고 싶다면, Color를 추가하고, 어떤 변수의 색상을 구분하고 싶은지 지정해 주면 된다.
# 모양 심미성 매핑, 모양으로 구분 (최대 6개까지 가능) ggplot(data = mpg) + geom_point(mapping = aes(x=displ, y=hwy, shape=class))
그래프를 표현하다 보면, 직접 조건을 넣어 구별하고 싶을 때도 있다. 이 때는 변수에 조건식을 넣어주면 ggplot2가 알아서 True/False로 구분해준다. 색상구분만 해보자면, ( 색상, 크기, 모양, 투명도 모두 적용 가능 )
# Color에 조건을 넣어주면, 조건에 대한 True/False로 색상을 구분 # cyl 변수는 차량의 기통 수 ( 즉, 8기통 보다 크냐, 작으냐로 True/False 색상 구분 ) ggplot(data = mpg) + geom_point(mapping = aes(x=displ, y=hwy, color=cy<8))
차형식(Class) 변수를 심미성 매핑( 색상, 모양 등 구분 )을 하면 차형식 안의 변수가 7개이기 때문에 복잡해 보이기도 한다. 어떨 때는 그냥 아예 그래프를 쪼개서 보는 것이 유리 할 수도 있다. 이때는 면 분할 함수 Facet_wrap를 추가하면 1개의 변수를 기준으로 쉽게 그래프를 분할 가능하다.
※ 아래 코드형식을 보면 Facet_wrap 함수를 +로 추가한 것을 볼 수 있다. 이처럼 ggplot는 +로 함수들을 추가하여, 기능이나 표현을 추가한다는 것을 볼 수 있다.
# 플롯을 하나의 변수에 대해 면 분할 Facet_wrap() # (중요) Facet_wrap()에 전달하는 변수는 이산형(연속형 X)이어야 함. # 이산형이란 것은 정수형, 문자형 Data가 뚝뚝 끊어져 있어야 한다는 것. # nrow = 그래프 분할 시 몇개의 행으로 구분하는지 지정 ( 굳이 안써도 됨 ) ggplot(data=mpg) + geom_point(mapping = aes(x=displ, y=hwy)) +facet_wrap(~ class, nrow=2)
여기서 더 욕심을 내면, 2개의 변수로 그래프를 쪼개고 싶을 때가 있다. 이 때는 Facet_grid()를 추가하자.
# 플롯을 두 변수 조합으로 면분할 Facet_grid() # 두개의 변수가 ~로 행, 열 구분됨 ( 변수를 생략하려면 .을 찍음 ) ggplot(data=mpg) + geom_point(mapping = aes(x=displ, y=hwy)) + facet_grid(drv ~ cyl)
<참고> Code 작성시 주의 사항
# 실행 안됨 ggplot(data=mpg) + geom_point(mapping = aes(x=displ, y = hwy))
# 실행됨 ggplot(data=mpg) + geom_point(mapping = aes(x=displ, y = hwy))