※ 해당 내용은 ADP 준비를 위해 데이터 마트 부분을 학습하며 정리한 내용입니다.
. 데이터 마이닝에서의 모델링
→ 다양한 분석 기법을 적용해 모델을 개발하는 과정, 데이터 마트를 개발해 놓으면 효율적이고 신속한 모델링 가능.
. 데이터 마트
→ 데이터의 한 부분, 특정 사용자가 관심을 갖는 데이터들을 담은 비교적 작은 규모의 데이터 웨어하우스.
. [참고] 데이터 웨어하우스와 마트 비교
→ 사용자의 기능 및 제공 범위를 기준으로 구분함.
→ 웨어하우스=전체의 상세 Data / 마트=특정 사용자 대상, 웨어하우스에 있는 일부 Data
1. R reshape를 활용한 데이터 마트 개발
① reshape
reshape는 데이터 재정렬을 위한 기법 중 하나, 비견될 수 있는 기법 중 밀집화가 있다.
. [참고] 밀집화
→ 데이터를 축소하고, 재정렬 ( ex) Excel Pivot )
→ 밀집화는 데이터가 간단하게 표시되지만, 원본이 손실되고, reshape는 원본이 유지된다는 점에서 차이가 있다.
. melt() & cast 함수
→ reshape 패키지로 melt(), cast()만을 사용하여 데이터를 재구성 or 밀집화된 Data를 유연하게 생성 가능
→ melt로 데이터를 녹여 유연하게 만든 후 피벗과 비슷한 cast로 모양을 잡아준다고 생각하면 됨.
library(reshape)
names(airquality)
names(airquality) <- tolower(names(airquality)) #소문자 변환
# id에 있는 변수를 기준으로
# 각변수 Variable이란 이름의 데이터로 만듬
# [참고] na.rm = 결측값 제거
aqm <- melt(airquality, id=c("month","day"), na.rm = TRUE)
aqm
# cast를 이용해 엑셀의 Pivoting을 하듯이 자료를 변환
# cast( data, y축~x축~값 )
a <- cast(aqm, day~month~variable)
a

mean을 적용해 평균값을 산출할 수도 있다.
b <- cast(aqm, month~variable, mean) # 월별 평균값 계산
b

|를 이용하여 산출물을 분리해 표시도 가능하다. ( 조회에 적합 )
c <- cast(aqm, month ~ .|variable, mean)
c

margin 함수로 행/열의 소계도 산출 가능
# 행과 열의 소계 산출
d <- cast(aqm, month~variable, mean, margins=c("grand_row", "grand_col"))
d

특정 변수만 처리하고자 할 때 subset 옵션을 추가
# 특정변수만 처리하고자 할 때
e <- cast(aqm, month~variable, mean, subset = variable=="ozone")
e

range 옵션을 추가하면 min, max를 동시에 표시해 준다
# min, max 표시 ( min=_X1 / max=_X2 )
f <- cast(aqm, month~variable, range)
f

2. sqldf를 이용한 데이터 분석
sql를 R에서도 사용할 수 있도록 하는 패키지, 단순히 sqldf 괄호 안에 SQL 언어를 입력하여 사용하면 됨.
data(iris)
sqldf("select * from iris limit 10") # head와 같은 기능 구현

3. plyr : 데이터 분리+처리 후 결합
ply 함수와 multi-core 사용 함수를 이용하면 for loop를 간단하고 매우 빠르게 처리 가능
ply() 함수는 앞에 두 개 문자를 접두사로 가진다.
첫 번째 문자=입력하는 데이터 형태, 두 번째 문자= 출력하는 데이터 형태
[ 접두사(데이터형태) 종류 ]
가. d = 데이터 프레임 ( data.frame )
나. a = 배열 ( array )
다. l = 리스트 ( list )
실습에 사용할 Data 생성
set.seed(1) # 난수 고정, 같은 난수를 생성하도록 해줌
# runif( 생성할 난수 개수, 최소값, 최대값)
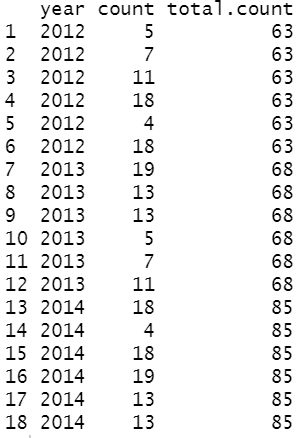
d = data.frame(year = rep(2012:2014, each=6), count = round(runif(9,0,20)))
d
. ddply을 사용해 데이터 프레임을 입력받아 sd와 mean의 비율인 변동계수 cv 구하기
→ test 결과 Rcpp 패키지도 추가해 주어야 함
library(plyr)
library(Rcpp)
ddply(d, "year", function(x){
mean.count = mean(x$count)
sd.count = sd(x$count)
cv = sd.count/mean.count
data.frame(cv.count=cv)
})

. transform, summarise 옵션
→ summarise 옵션 = 변수에 명령된 평균이나 합 등을 계산해 줌
→ transform 옵션 = summarise 옵션과 달리 계산에 사용된 변수도 출력
ddply(d, "year", summarise, mean.count = mean(count))

ddply(d, "year", transform, total.count = sum(count))
4. 데이터 테이블 ( Data Table )
데이터 테이블은 데이터 프레임과 우사하지만 보다 빠른 그룹화, 순서화, 짧은 문장 지원 측면에서 매력적
data.frame과 같은 방법으로 생성되나, 행 번호가 콜론(:)으로 표시
# rnorm(n) 함수는 정규분포에서 n개의 난수 생성
DT <- data.table(x=c("b","b","b","a","a"),v=rnorm(5))
DT

기존 data.frame을 data.table 형식으로 변환 가능하다.
CARS <- data.table(cars)
. data.frame과 data.table 차이점
→ 데이터 테이블 = 인덱스(목차) 생성이 가능한 데이터 프레임
→ 따라서 검색과 같은 작업을 할 때 성능의 차이점을 보인다.
→ [참고] 검색 시 data.frame은 하나하나 비교해 찾는 벡터 검색 방식 / data.table은 목차를 이용, 바이너리 검색
'Programming > R _ Data' 카테고리의 다른 글
| [ADP/4과목③] 데이터 분석 _ 결측값 처리와 이상값 검색 (0) | 2021.09.29 |
|---|---|
| [ADP/4과목①] 데이터 분석 _ R 기초 (0) | 2021.09.26 |
| [ R ] ggplot2 막대 그래프 그리기 ( geom_bar() ) (0) | 2021.05.24 |
| [ R ] ggplot2 기하 그래프 그리기 ( geom_smooth() ) (0) | 2021.05.23 |
| [ R ] ggplot2 다양한 방식의 산점도 작성 ( geom_point() ) (0) | 2021.05.23 |




